Welcome to Palladium!¶
Palladium provides means to easily set up predictive analytics services as web services. It is a pluggable framework for developing real-world machine learning solutions. It provides generic implementations for things commonly needed in machine learning, such as dataset loading, model training with parameter search, a web service, and persistence capabilities, allowing you to concentrate on the core task of developing an accurate machine learning model. Having a well-tested core framework that is used for a number of different services can lead to a reduction of costs during development and maintenance due to harmonization of different services being based on the same code base and identical processes. Palladium has a web service overhead of a few milliseconds only, making it possible to set up services with low response times.
A configuration file lets you conveniently tie together existing components with components that you developed. As an example, if what you want to do is to develop a model where you load a dataset from a CSV file or an SQL database, and train an SVM classifier to predict one of the rows in the data given the others, and then find out about your model’s accuracy, then that’s what Palladium allows you to do without writing a single line of code. However, it is also possible to independently integrate own solutions.
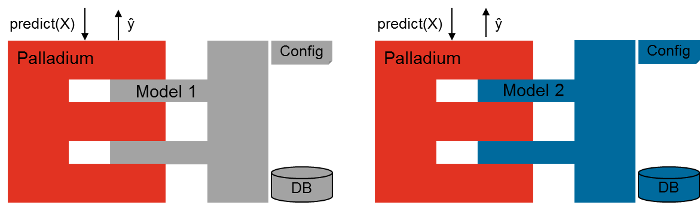
Much of Palladium’s functionality is based on the scikit-learn library. Thus, a lot of times you will find yourself looking at the documentation for scikit-learn when developing with Palladium. Although being implemented in Python, Palladium provides support for other languages and is shipped with examples how to integrate and expose R and Julia models.
For an efficient deployment of services based on Palladium, a script to create Docker images automatically is provided. In order to manage and monitor a number of Palladium service instances in a cluster, Mesosphere’s Mesos framework Marathon can be used for deployment, also enabling scalability by having a variable number of service nodes behind a load balancer. Examples how to create Palladium Docker images and how to use them with Mesos / Marathon are part of the documentation. Other important aspects – especially relevant in enterprise contexts for setting up productive services – like authentication, logging, or monitoring, can be easily integrated via pluggable decorator lists in the configuration file of a service, keeping track of service calls and corresponding permissions.
Links¶
- Source code repository at GitHub: https://github.com/ottogroup/palladium
- Documentation including installation instructions and tutorial: http://palladium.readthedocs.org
- Mailing list: https://groups.google.com/forum/#!forum/pld-list
- Maintainer: Andreas Lattner
User’s Guide¶
This part of the documentation is mostly prose. It starts with installation instructions for setting up Palladium for development, then develops a simple pipeline for predicting classes in the Iris flower dataset dataset. It will explain the concepts behind Palladium as it develops the application.
- Installation
- Tutorial
- Deployment
- Web service
- Scripts
- pld-fit: train models
- pld-test: test models
- pld-devserver: serve the web API
- pld-stream: make predictions through stdin and stdout
- pld-grid-search: find optimal hyperparameters
- pld-list: list available models
- pld-admin: administer available models
- pld-version: display version number
- pld-upgrade: upgrade database
- Upgrading
- R support
- Julia support
- Advanced configuration
- Frequently asked questions
- How do I contribute to Palladium?
- How do I configure where output is logged to?
- How can I combine Palladium with my logging or monitoring solution?
- How can I use Python 3 without messing up with my Python 2 projects?
- Where can I find information if there are problems installing numpy, scipy, or scikit-learn?
- How do I use a custom cross validation iterator in my grid search?
- Can I use my cluster to run a hyperparameter search?
- How can I use test Palladium components in a shell?
- How can I access the active model in my code?
- Related projects
API Reference¶
If you are looking for information on a specific function, class or method, this part of the documentation is for you.
- palladium package
- Submodules
- palladium.R module
- palladium.cache module
- palladium.config module
- palladium.dataset module
- palladium.eval module
- palladium.fit module
- palladium.interfaces module
- palladium.julia module
- palladium.persistence module
- palladium.server module
- palladium.util module
- palladium.wsgi module
- Module contents